[GIS]서울시 사업체 데이터(파일)를 통한 국지적 공간자기상관지표 시각화(LISA)
이번 포스팅은 공간적 자기상관이 무엇인지 간단하게 확인하고, LISA(Local Indicators of Spatial Association)에 대해 간단하게 알아보며, 서울시 사업체 파일을 통해 시각화하는 법에 대해 배워보자.
도시 내 관측되는 모든 데이터들은 공간에 영향을 받는다. 그렇기 때문에 반드시 공간적 자기상관성을 검정하여야한다.
- 공간적 자기상관성[Spatial Autocorrelation] : 공간적 자기상관성은 W. Tobler(1970)의 지리학 제 1법칙(The First Law of Geography)에 입각하여 “모든 것은 그 밖의 다른 모든 것과 연관되어 있지만, 인접해 있는 위치가 멀리 떨어진 위치의 관측치보다 더 높은 관련을 보인다”라고 정의할 수 있다.
공간적 자기상관성은 멀리 있는 지역보다 인접해있는 지역에 유사한 값을 가질 가능성을 의미한다. 일반적인 OLS모형의 경우, 독립변수와 오차항 값 모두 독립성을 가정하여 분석을 진행하는데, 이는 공간적 자기상관성을 고려하지 않는다고 볼 수 있다(조항훈&김흥순, 2023, 도시특성이 건축물의 탄소배출에 미치는 영향에 관한 연구 : 서울시 424개 행정동에 대한 공간회귀분석의 적용,LHI저널, 14(3):77-92).
이를 요약하자면, OLS(선형)회귀모형은 정규성(회귀모형에 대한 오차항이 정규본포를 이루는가?), 등분산성(분석 표본들의 차이, 분산이 동일한가?), 독립성(회귀모형에 대한 오차항이 상호간의 관계가 없으며, 독립적인가?), 공선성 배제(변수들 간의 상관성이 없거나 VIF 값 혹은 상관관계가 낮은가?), 공간적 자기상관성 배제(종속변수와 오차항 사이에 서로 공간적인 상관성이 없는가?) 등 총 5가지의 기본가정을 지켜야하는데,위에 기본 가정 상 하나의 문제가 발생하면 OLS모형을 사용할 수 없다.
따라서 공간적 자기상관성을 띄고 있는 자료를 이용하여 일반선형회귀모형을 적용할 시, 모형의 설명력이 과대 추정되고, 유의확률도 신뢰할 수 없는 문제가 발생한다(이희연&노승철, 2012, 고급통계분석론:이론과 실습, 문우사).
공간적 자기상관성을 고려한 모형을 구축하려면, 공간가중행렬을 이용하여 검정하고, 해결하여야한다. 공간가중행렬을 이용하여 공간적 자기상관성을 확인하는 모란지수(Moran’s-I, Morans I Statistic of Spatial Auto-correlation)는 보편적으로 공간자기상관성의 측정 척도로 사용된다.
일반적으로 전체 공간에 대한 패턴이 존재하지 않는다(Spatial Randomness)는 귀무가설을 가정하지만, 양(+) 혹은 음(-)의 자기상관관계가 나타난다면 모란지수를 통해 귀무가설을 기각할 수 있다. 모란지수는 대표적으로 전역적 모란지수(Global Moran’s-I)와 국지적 모란지수(Local Moran’s-I)로 구분된다.
전역적 모란지수는 인접 공간 단위들의 해당 값을 비교하여 Moran’s-I 계수를 산출하고, 계수 간 인접하고 있는 공간들이 유사한 값을 갖는 정적 공간상관과 서로 상이한 값을 갖는 부적 공간상관을 확인할 수 있다(서수복, 2015, 지가변동의 시대별 공간적 특성에 관한 연구, 국토연구 8:23-34).
일반적으로 전역적 모란지수는 음(-)의 공간자기상관인 -1에서 양(+)의 공간 상관인 1사이의 값을 가지기 때문에 0을 기준으로 1사이의 값을 가지면 공간적 자기상관이 나타나고, -1 사이의 값을 가지면 균등분포가 나타난다고 볼 수 있는데, 이를 정리하면 아래 식과 같다(이희연&노승철, 고급통계분석론:이론과 실습, 2012, 법문사).

여기서 N은 지역 단위 수, Yi는 i 지역의 속성, ȳ는 지역의 평균값, wij는 공간단위의 가중치(i와 j지역별)를 의미한다. 공간적 단위가 i 혹은 j가 평균 값보다 크거나 작을경우, 이들의 곱은 양수의 값을 갖게되어 인접한 공간 지역들의 경향성이 강한 양적(+) 공간 자기상관이 나타나게된다. 반면, 공간 단위 i가 평균 값보다 크고, j가 평균 값보다 작을 경우, 음수가 되어 규칙적으로 분포하는 공간 패턴인 음적(-)공간 자기상관을 갖게된다(김광구, 2003, 공간 자기상관의 탐색과 공간 회귀분석의 활용, 정책분석학회보, 13(1):273-306).
한편, 전역적 공간 자기상관(Global)은 전역적 통계량만을 보여줌으로서, 특정 지역의 군집성을 파악할 수 없다는 한계점이 존재한다. 이러한 한계점을 극복하고자 국지적 변이를 고려하고, 공간적 차원에서 자기 상관의 위치를 확인할 수 있는 국지적(Local) 모란지수를 사용하여야하는데, 아래 식과 같다.
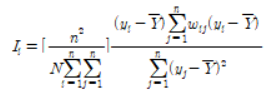
국지적 모란지수는 인접 지역 간 수치적 유사성을 근거로 양(+)의 공간적 상관성이 형성되는 핫스팟(Hot spot)과 서로 상이한 값들을 근거로 음(-)의 공간적 상관성이 형성되는 콜드 스팟(Cold spot)으로 표현되며, 특정 지역이 전체 지역 간 공간적 자기상관에 얼마나 영향을 미치는 지 파악할 수 있다. 국지적 모란지수는 대표적으로 국지적 공간자기상관지표(LISA)를 통해 관측할 수 있으며, 관측 단위별로 산출하여 시각적인 지표로 표현된다(강호제, 2008, 핫스팟 분석기법(Hot Spot Analysis) : 공간분석의 기초, 최근린 군집 분석과 국지모란지수의 이해와 활용, 국토연구, 324 : 116~121).
본 포스팅에서는 위와 같이 전역적 모란지수(Global Moran’s-I)와 국지적 모란지수(Local Moran’s-I)에 대한 정의를 서술하였다. 그렇다면, 이제 실습을 통해 활용방법을 알아보자.
예제는 소상공인과 기업체(개소)의 값이 들어있는 사업체 데이터를 활용해보자.
사업체 데이터는 다양한 사이트에서 제공하는데, 서울시 소상공인 빅데이터 저장소, 서울열린데이터광장, 공공데이터 포털 등에서 자료를 신청하거나 다운받아 활용할 수 있다.
사업체를 측정할 수 있는 사이트는 많지만, 필자는 공공데이터 포털에서 자료를 다운받아 활용하고자 한다.
- 서울시 소상공인 빅데이터 저장소 : https://www.sdatadam.co.kr/manual
- 서울열린데이터광장 : https://data.seoul.go.kr/
- 공공데이터 포털 : https://www.data.go.kr/
필자는 이전에 포스팅(서울시 경사도 래스터 파일을 백터화)한 내용을 바탕으로 서울시를 400m 격자로 추출하고, 서울시 4,049개 격자 내 사업체 수를 공간조인하여 격자 내 사업체 수를 할당하였다. 이후 공간 조인된 데이터(shp) 통해 모란지수를 측정하고자 하였다. 이를 위해 Tools의 Weights Manager을 Creat하여야 한다.
 |  |
Select ID Variable은 FID를 기준으로 설정하고, Queen 형식으로 하였다. 여기서 공간가중행렬 설정 방식에서는 Queen, Rook, Bishop 방식이 존재(체스와 비슷)하는데 각 인접방식에 대한 차이가 있음을 알 수 있다.

이후, 전역적 혹은 국지적 공간자기상관성을 확인할 수 있는데, 필자는 먼저 전역적 공간자기상관성을 확인하기 위하여 Space에서 Univariate Moran’s I 를 선택한 후, 종속변수(사업체)에 대한 공간적 자기상관성을 검증하고자 해당 변수들 중 사업체를 선택하였다. 그 결과, Moran’s I 값은 0.6으로 도출되었으며, 999Permutations(유의수준 0.001 수준)에서 Z-Value가 72.2974로 도출되어 공간적 자기상관성이 강하게 나타나는 것을 확인하였다.

한편, 필자는 전역적 공간자기상관으로는 특정 지역의 자기상관성을 확인할 수 없어 Space에서 Univariate Local Moran’s I 를 선택한 후 사업체 변수에 대한 LISA분석을 실시하였다. LISA 분석 값은 모란 산포도 (Moran Scatter plot)를 통해 보여주는데, 주변과의 공간적 연관성을 4가지 유형으로 구분하여 보여준다. 세부적으로 관측값을 기준으로 높은 값 주변에 높은 값인 H-H(High High), 낮은 값 주변에 낮은 값인 L-L(Low Low), 낮은 값 주변에 높은 값인 L-H(Low High), 높은 값 주변에 낮은 값인 H-L(High Low)로 표현된다고 볼 수 있다.
필자가 보고 싶어하는 서울시 격자 내 사업체의 밀집을 확인하기 위해 LISA분석을 실시한 결과 도심, 강남, 영등포 외에도 관악구와 마포구 일대에서 H-H 군집이 집중적으로 관측되었으며, p < 0.01 또는 p < 0.001 수준에서 통계적으로 유의한 공간 클러스터로 나타났다.

도심지(CBD)는 전문적인 기능이 수행되는 중심업무지역으로써 사회·경제적인 주요도가 가장 높은 곳이며, 도시 내에서 보행자의 유동과 교통 밀도가 가장 높게 형성되는 곳이다. 또한, 마포구와 관악구 일대의 경우 주변에 대학가를 포함하여 서울시에서 지정한 발달 상권과 골목 상권 두 영역이 혼합된 지역으로 볼 수 있다. 서초구 및 강남구(GBD) 일대의 경우 상업이나 그 밖의 업무기능의 편익을 증진하기 위하여 지정된 중심상업지역으로 모든 지역으로부터 접근성이 용이한 곳으로, 고밀화·고도화에 적합한 지형의 조건을 가지고 있으며, 영등포(YBD)는 업무기능과 교통접근성이 가장 높은 지역으로 뽑힌다(서울시, 2023, 2040서울도시기본계획, 서울도시공간포털).
이번 시간에 필자는 공간적 자기상관성(모란지수)이 무엇인가에 대해 파악하고, 서울시 격자 내 사업체 수를 통해 공간 클러스터가 된 특정 지역이 어디인지를 확인하였으며, 모든 연구자들의 참고용이 되었으면 좋겠다는 바람이 있다.
'GIS' 카테고리의 다른 글
| [GIS]서울시 경사도 데이터 (42) | 2025.10.01 |
|---|
